1.前言
之前有一篇博客是介绍了搭建mongodb的replica set集群的。
这次系列将会对mongodb做一个更为详细的介绍,这篇主要讲的是mongodb数据分片集群的搭建。
分片(sharding)、副本集(replication)与分布式文件系统(比如 hbase)的区别:
- 副本集集群中的每一个节点的数据都是相同的,有一个primary,1~7个secondary,数据写入primary节点后会同步给所有的备份节点,可以很方便地作读写分离。还有一个可选的arbitary节点,当primary节点宕机后,由arbitary节点从secondary中选出新的primary节点。如果没有arbitary,则由所有secondary节点共同决定下一个primary节点。
- 数据分片集群中,每一个数据节点存的数据都是不同的,互作补充。由预先定义的字段或者组合字段作为分片的依据。往集群中新增分片节点,数据库会自动作数据迁移,使得存储负载尽可能平均。(某个节点挂了,部分数据访问不了怎么办,如何作数据的高可用?)
- 分布式文件系统是文件系统,数据库是一种定义的数据存储格式。数据库的数据在文件系统中也是以多个文件的形式存储的,而文件就是存储在文件系统中的。
mongodb支持数据的分布式存储,将collection作数据分片,减少每个节点的数据负载。
每个节点可以位于不同的物理机器上,一个简单的sharding集群如下图所示(引用自mongodb官网):
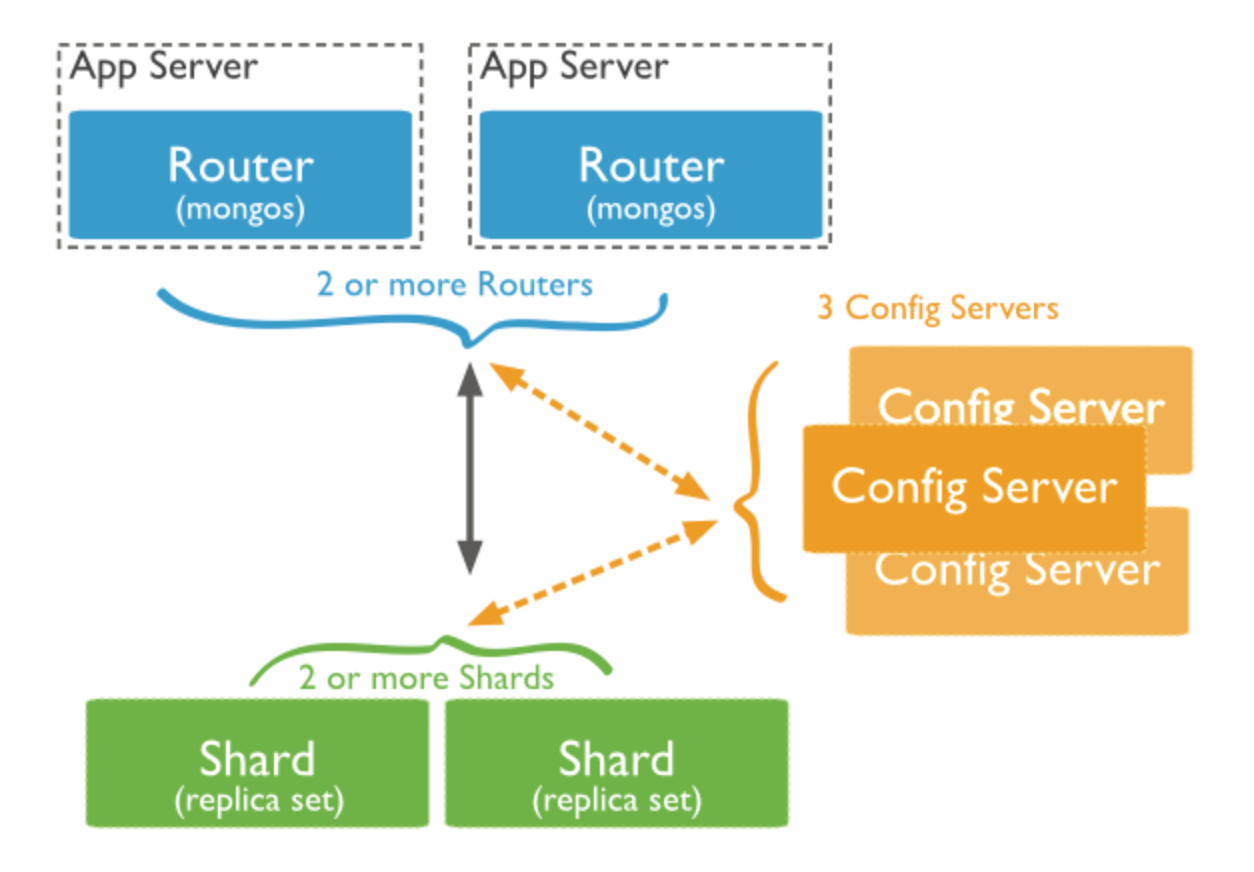
三部分:
- 多个mongos节点,用作路由
- 3个config server,记录了所有数据分片存储位置
- n个sharding server,数据真正落地的地方
2.创建configServer
创建数据库目录
1 | mkdir ~/Desktop/configdb_1 |
启动config server 进程
1 | mongod --configsvr --dbpath /Users/wangyue/Desktop/configdb_1 --port 9801 --fork --logpath /Users/wangyue/Desktop/configdb_1/mongod.log |
3.创建mongos进程
1 | mongos --configdb 127.0.0.1:9801,127.0.0.1:9802,127.0.0.1:9803 --port 9800 --fork --logpath /Users/wangyue/Desktop/mongos.log |
4.添加数据分片服务器
一个数据分片可以是一个单独的mongod进程,也可以是一个副本集集群。
把数据分片节点配置成副本集在生产环境中是最常用的做法,可以保证数据分片节点一定程度的高可用。
4.1.启动3个数据分片服务器
创建数据库目录
1 | mkdir mongodb_1 |
启动数据分片
1 | mongod --dbpath /Users/wangyue/Desktop/mongodb_1 --port 9804 --fork --logpath /Users/wangyue/Desktop/mongodb_1/mongod.log |
4.2.连接mongs服务器
1 | mongo --host 127.0.0.1 --port 9800 |
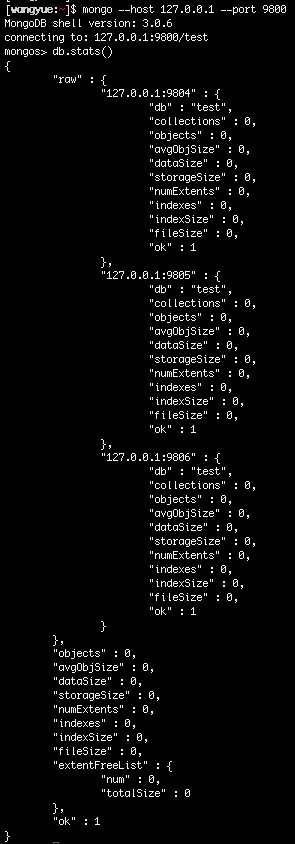
执行 db.stats() 可以看到详细信息:
5.启动数据分片
1 | # 连接mongos |
- 如果不用hash分片的话填入 1, 也可以支持多个index联合作为分片的字段
6.数据插入测试
- 插入10000个数据
1 | import pymongo |
数据在节点中的分布



mongo客户端可以单独连接每个数据分片,作一些增删改查
(虽然不推荐这么做,但这个特性提供了很大的可能性去做别的事情)