背景及介绍
最近接触一个项目,用到了celery, 故对其作一个学习和了解。celery是一个基于Python开发的并行分布式框架,在github上可以找到。
它其实是一个协议,因此是语言无关的,目前也有其它语言的实现版本比如ruby的RCelery。
实践
看了网上的资料,大概对于它的工作模式有一个认识,但对于如何使用它的api还是有点困惑,因为我感觉文档中的demo代码展示得不够透彻,还不能完全地说明这api是如何工作的。因此我在慢慢探索的过程中,整理了自己的demo版本,并运行了一下,这才有了更深的认识。
关于celery的数据存储中间件,选择有很多,比如redis,rabbitmq等,甚至数据库也支持,我实验时选择了redis。
编码
由于是一个异步队列,很经典的生产者消费者模式,因此需要编写两个文件,分别是生产者和消费者:
消费者
1 | # celery_worker.py |
生产者
1 | # celery_producer.py |
在这里两个add函数以及Celery中的第一个参数都不一样,其实是我故意的,原因后面会慢慢分析。
执行
消费者
celery是一个python包,同时自己也是一个命令,执行消费者的时候,可以通过以下命令执行:
1 | celery -A celery_worker worker --loglevel=info |
这里的-A选项表示要执行的celery app的名字,也就是当前目录下的celery_worker文件。我开了两个窗口,分别执行以上命令,输出如下(两个窗口都一样,这条命令会阻塞窗口):
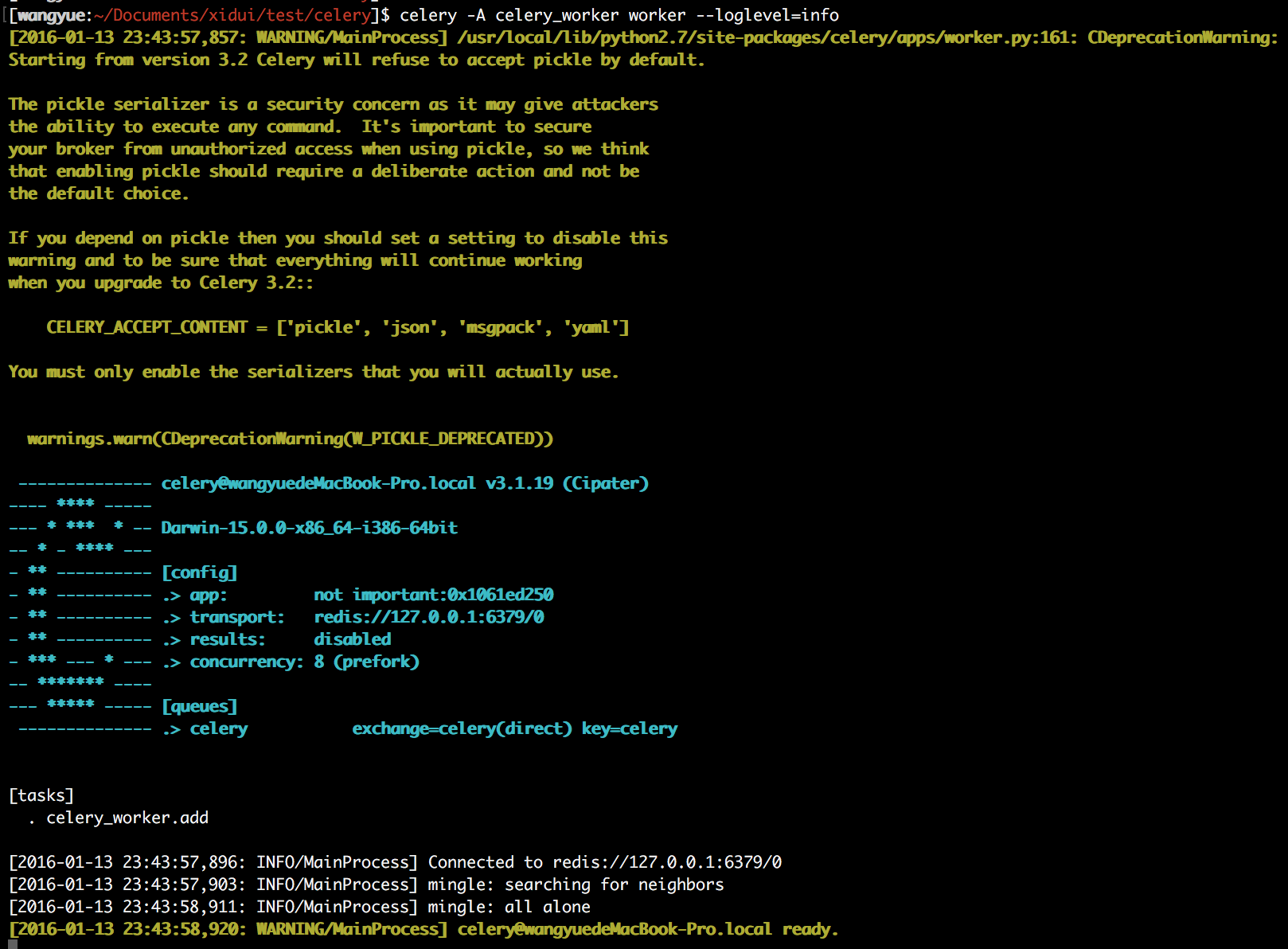
可以从[tasks]里看到,它定义了任务的类型是celery_worker.add,同时fork了8个进程(默认是计算机cpu的核数)并发处理任务,任务是由master进程从redis中读取的(估计是轮训吧,redis有通知机制吗?可以去调研下)。
生产者
生产者通过python执行就可以了:
1 | python celery_producer.py |
它给celery_worker.add送了100个任务,从两个窗口都可以看到类似的内容,截取其中一部分:
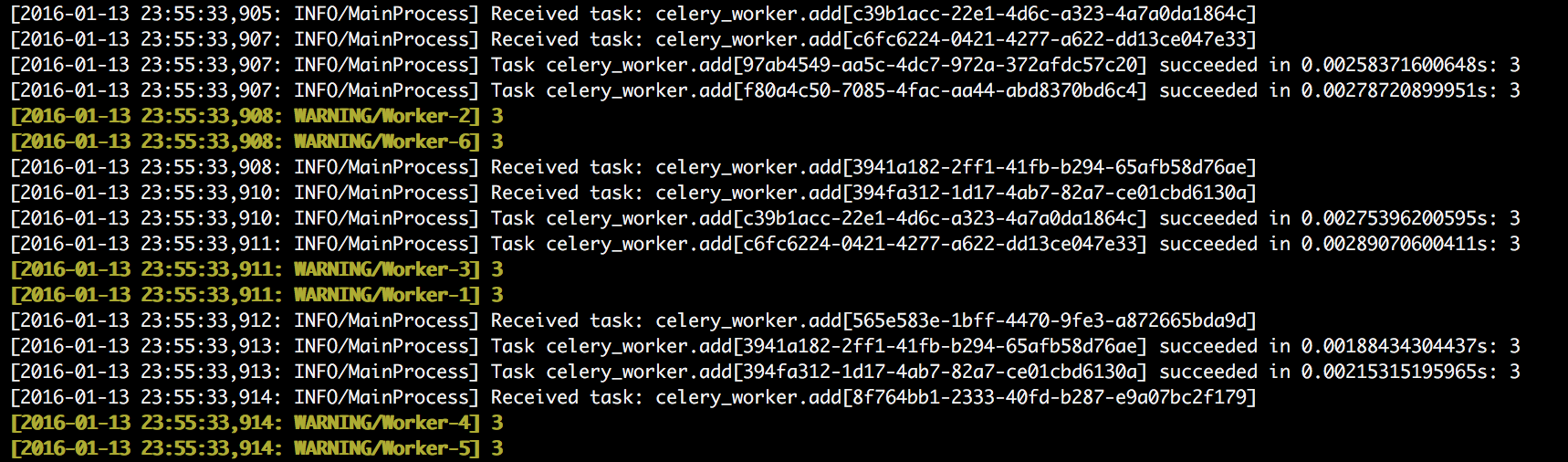
可以看到两个workers集群都可以接受到任务,同时它们的和是100(并不会有任务被忽略,也不会有任务被执行两次)。
总结
总结之前,先贴上大部分网上文档中的生产者代码(消费者代码基本一致):
1 | from celery_worker import add |
它直接引入了worker中的add方法,这个有几点不好:
- 没有体现celery的分布式特性
producer和worker在代码层面上耦合,读者很容易误解,以为这两者必须要放在同一个项目里。事实上它们完全可以分开producer和worker作为不同的文件可以单独跑在不同的机器上,只需要保证它们连着相同的数据存储中间件即可。 - 没有体现协议上的松耦合
会让读者造成,producer要给worker发任务,必须要调用worker中定义的原来的方法。事实上,只需要调用一个定义在相同的命名空间(celery_worker)下的同名的方法就可以了(甚至连参数个数都可以不一样),任务队列只通过命名空间以及方法(celery_worker.add)去辨别不同的任务。可以从worker的输出看到:1
[2016-01-13 23:55:33,905: INFO/MainProcess] Received task: celery_worker.add[c39b1acc-22e1-4d6c-a323-4a7a0da1864c]
还有其它的特性:
3. worker的命名空间不是由传入Celery的参数决定的
而是启动命令的app名称(也就是worker的文件名)决定的。虽然从输出看,他的app名称是not important,但它的tasks却是celery_worker.add
顺便分享一篇文章celery最佳实践