前言
细细回想这几周经历的问题以及过程,还是真是挺有趣的,迫不及待地希望整理一下总结给各位看官。
关于文章的标题,如何既能吸引读者,又能避免标题党的嫌疑,着实让我斟酌了一番,后来就定了在坐看到的这个版本,个人觉得没毛病~
让我们进入正题
阶段一
3月10日
leetcode完成主数据库迁移,一步步往分布式架构扩展
3月15日
收到了一封黑客的邮件,说发现了系统漏洞,并勒索

3月17日中午
发现user ranking功能失效
经检查,是因为我们迁移了主数据库的原因。老数据库所在的机器有一个daily job每天自动更新用户排名。由于新数据库机器的ip不一样,导致脚本过去7天都没有正常工作。于是修改了配置,继续投入使用。
3月17日下午5点
不少用户在twitter抱怨无法登陆,我自己也试了一下,确实无法登陆。但是除了登录api,其它所有的api都没有问题,已经登陆的用户也都能正常做题。



这不禁让我们想到了2天前收到的黑客邮件,怀疑黑客正在攻击。于是开始检查各种系统参数和日志。检查到旧的数据库所在机器,有一个很奇怪的参数,发现mysqld进程的cpu占用率将近100%,明明这个旧的mysql已经弃用了,到底是谁在里面呢?登录mysql去一探究竟:

不断刷新发现这个用户执行的sql语句由comment_id一条条进行累加,断定有人在 恶意拖库。
为了安全起见,在排查前,我们决定 关闭nginx,关闭整个网站。
这个mysql账户是我们旧的wordpress后台配置的,这个网站(https://article.leetcode.com)是我们之前用过的子站点,现在也已经弃用了,为了让以前的链接依然可以工作,我们并没有关闭这个站点。
排查逻辑:
- mysql账户的登录权限只有localhost,排除远程登录执行sql的可能
- mysql账户的密码只配置在本机,服务器并没有开放root登录权限,sudo账户的密码又极其复杂,排除暴力破解服务器密码的可能
- 通过服务器登录记录(last 命令),并没有发现可疑ip
因此,断定这些sql只能是通过wordpress代码在执行。然而,wordpress并没有开放任何一个api可以去通过id遍历某张表。只能是 sql注入!!!
经查,确实是sql注入。这是由某个过时的wordpress插件带来的问题,网上也有针对这个bug一模一样的sql注入流程,有兴趣的读者可以戳这里看看。
定位问题后,我们关闭了article.leetcode.com,并启动网站,当天用户无法登陆的问题消失了。
安全性分析
- 由于我们的服务器密码并没有泄露,不需要更换服务器和账户
- 被拖的库只是弃用的db中弃用的表,没有什么敏感信息
- 即使主库被攻破,用户密码是经过hash存储的,攻击者并不能直接获益
- 由于无法获得sql执行记录,不知道在这张表被拖库前,黑客还做了什么其他的事情,这点尚有担忧
总体来说,这次被攻击对网站带来的损失不大,但也让我们一身冷汗。
阶段二
如果这件事情就这么结束了,那就再好不过了。然而,用户无法登陆的问题,在后面的几天持续出现,而且每天都会完整持续1小时以上,不禁让我们陷入沉思。莫非黑客还在?但是我们不管怎么找都没有发现什么蛛丝马迹,看着每天用户在论坛抱怨,感觉心急如焚,但又不知道该如何是好,哎!
3月20日~3月24日
每天我们都会监控用户登录失败的情况,然后在持续登录失败的时段内,发现了如下规律:
- 网站请求数量并没有指数级的增长
不光没有指数级,基本如同往常。这点排除了 DDOS攻击 的可能。 - 数据库的CPU占用并没有明显增加
说明并不是过大的数据库负载导致了响应变慢。同时,其它接口的响应速度都很快,验证了这个推断。 - 数据库的processlist有不少user表的update记录阻塞
 用户登陆的时候会触发数据库写操作,更新上次登录的时间。这些简单的update语句持续阻塞,只能说明一个原因,表单记录被其它 transaction 锁住了
用户登陆的时候会触发数据库写操作,更新上次登录的时间。这些简单的update语句持续阻塞,只能说明一个原因,表单记录被其它 transaction 锁住了 - 通过
show status like '%lock%'发现锁的时间不断增长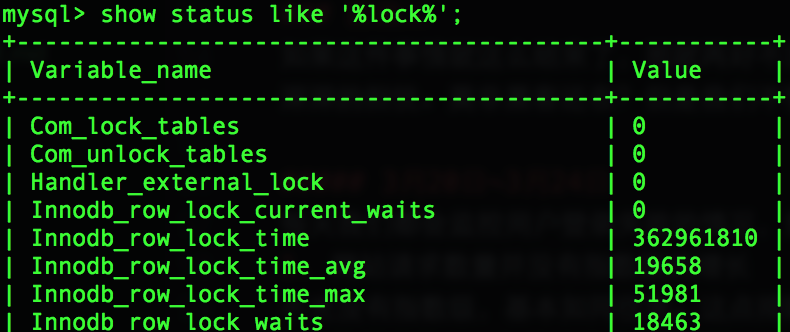
- 通过
show engine innodb status发现了一堆锁的记录,而且在不断地变多
果然是锁的问题。但是,到底是谁,是什么操作导致了这么多锁?谁会锁定user表?还是没有任何头绪。
3月25日下午5点
网站一如既往地登录超时,在外面参加聚会的我不得不拿出电脑,继续排查(今后若是有聚会,各位朋友请包容我这随身携带笔记本的习惯~)。这个时候,我在new relic监控发现了一个值得关注的信息:
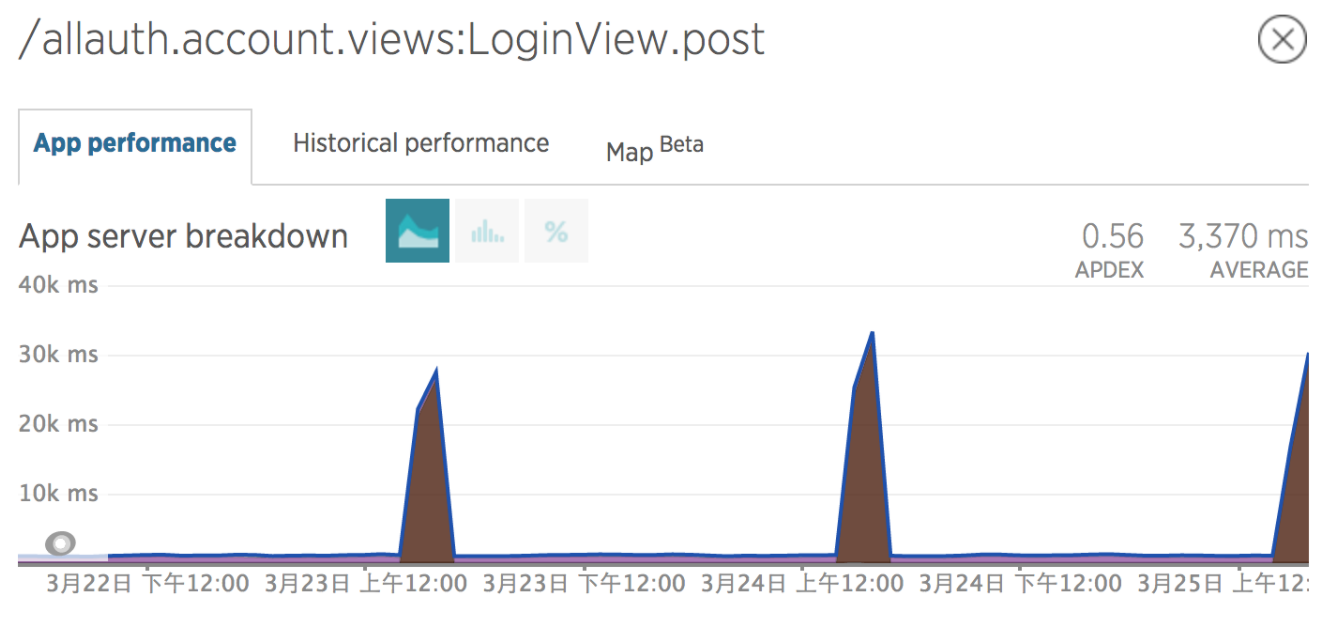
网站出现登录超时的情况是有迹可循的,每天固定在同一个时间出现一次。难道黑客攻击还会有一个定时任务吗,而且都是攻击一小时左右,显然不太可能。莫非这是一个我们自己的定时任务?
突然想到了我们的 user ranking脚本,而且每天发生登录超时的时候正好是脚本定时执行的时候!!!这简直是突破性的信息,因为如果真是这个脚本造成的话,那我们就排除了黑客在恶意登录用户账户的可能。
这个时候又一个新的问题来了
user ranking脚本只更新user_ranking这张表,为什么会锁住user表导致无法登录呢?而且它只锁了user表,网站的其它任何操作都能够顺利执行,已登录用户的做题完全不受影响。
因为还在聚会,也确定没有什么大问题,mark了一下以后,留待第二天继续检查。
3月27日下午5点
登录失败的情况准时出现了,我马上kill掉了user ranking定时任务。登录失败的情况瞬间好转!!!自此,基本已经确定是该脚本导致的问题。这时,问题只剩一个了:为什么更新user ranking表的时候,会锁住user表?
3月28日
定位到问题之后,我在本地测试环境也重现了这个问题,这大大降低了调试的难度,不需要去线上调试了!
同时,查阅了各种mysql lock的文档,试图了解数据库何时会产生锁,何时会释放锁。同时仔细阅读了user ranking脚本,下面截取的某个值得怀疑的代码段(考虑到网站的隐私,我把字段和表格改了名字):
1 | for index, (user_id, ac_count) in enumerate(sort_list): |
commit操作为什么要放在最外面呢?
测试环境尝试了一下,如果把commit操作放在for循环里面,登录失败的情况就不会出现。同时,数据库里的lock数量和lock时间并不会增长。果然,数据库的transaction要通过commit才能结束,然后才能释放它所占有的锁。user_ranking表和user表之间是通过user_id作为外键的,莫非?
手动去掉了这个外键的限制,我发现即使把上一步的commit操作放在for循环外面,也不会导致登录失败。看来,transaction在更新一条记录的时候,不仅会锁住相应记录本身,还会通过外键把其它表的相应行也一起锁住
自此,这个问题终于浮出了水面!原来是这个历史遗留脚本的一个小错误,导致了这个莫名其妙的登录失败问题。解决的办法很简单,把commit那一行,挪入for循环。如果考虑transaction提交次数太频繁,可以每隔一定数量sql后,再执行commit。
那么问题来了
挖掘机哪家强?当然不是这个问题~
为什么这个登录失败的现象在数据库迁移之前没有发生,而迁移之后发生了呢?(略有经验的)我想想就得出了结论(前文也有所提及),user ranking脚本之前是和数据库跑在同一台机器的,而迁移之后,跑在了不同机器,大大增加了网络的时间成本。一次网络传输的时间可能可以忽略不计,如果百万次网络来回的时间,那可就不是小数目了,毕竟脚本中for循环每执行一次,至少就是一次网络传输。
将user表的条目乘以网络延迟的时间,果然是一个多小时! (敏锐的读者或许已经可以根据我的信息得到某些其它的东西了,不再透露更多,对于本文也不重要)。
好奇的我又在老数据库上执行了一遍脚本,1分钟就完成了。原来如此,怪不得之前一直没有用户抱怨登录失败的问题。一来 是因为user表被锁的时间太短,几乎没有用户受到影响(已登录用户是通过session保留登录态的,不需要调用登录操作)。二来 是因为之前的脚本不是一次性锁住所有用户的,而是通过一条条语句,逐渐增加的。
总结
关于这件事的总结
一个mysql锁的问题和一个黑客sql注入的问题混杂在了一起,导致这个bug本身难以被发现。通过孜孜不倦的努力,终于还是把它查得水落石出,畅快淋漓啊!
本次事件有诸多巧合
- 黑客敲诈的时间和数据库迁移的时间正好重叠
- 黑客声称能登录任何账户和这个bug所体现的现象非常符合
- 修改脚本配置,导致用户登录失败。通过排查这个bug,我们才发现了黑客,让我们注意力集中到了黑客身上,从而忽略了这个bug本身
我们有告诉黑客,愿意以金钱购买他所说的漏洞,但他并没有回复,直接开始攻击。在解决问题之后,网站并无任何异常,他也不再进行进一步勒索,由此推断他手中已无底牌。当初的声称可能只是吓唬,以提高他能勒索的金额,通过sql注入来告诉我们他确实有几张牌。
对于网络攻防更有经验的读者希望可以告知一些我们在排查过程中做的不足的地方,加以学习,感激不尽!
事件之外的总结
- 分布式软件架构的复杂度会随着分布式规模的增大而增大。单机或者小规模集群中没有体现的问题,会在规模变大之后被无限放大。
- 没事儿,少折腾数据库。或者说在不够了解系统和数据库配置的情况下,折腾数据库的风险是巨大的,我将会有一篇文章详细介绍leetcode数据库迁移的过程,敬请期待。
- 分布式系统问题的排查,需要关注方方面面,远比单机困难的多。对于小公司系统的扩容,最佳的做法是增加服务器的性能,其次才是考虑分布式架构的演变,因为这将大大增加维护成本。
- 对于业务导向的小公司来说,如果暂时系统的高可用性不是首要的需求,使用足够强的单机,就足以支撑你们当前的业务了。而且一般的网络主机供应商所能提供的高可用性至少也有3个9(99.9%)。如果你们的业务已经强大到单机无法支撑,那么恭喜你们,你们离融资和扩张不远了。