模块加载原理
nodejs中,一共有四种类型的模块,C++核心模块(内建模块),js核心模块,C++用户模块,js用户模块。这部分来分别探讨下这些模块的编译加载流程。
问题:
1.require、exports、module这些对象用户没有声明过,但用户还是可以直接用require(),exports,这是为什么?
2.引入别的模块的流程如何?
1.js核心模块加载原理
每个js模块都是一个文件,一个文件一个模块,在js代码中就是一个Module对象。至于那些整个包构成的模块,也是有一个对外的文件,如果没有指定默认是index.js作为出口文件,该文件内部又会使用require去包含其它的文件。
核心模块加载的大致流程如下:
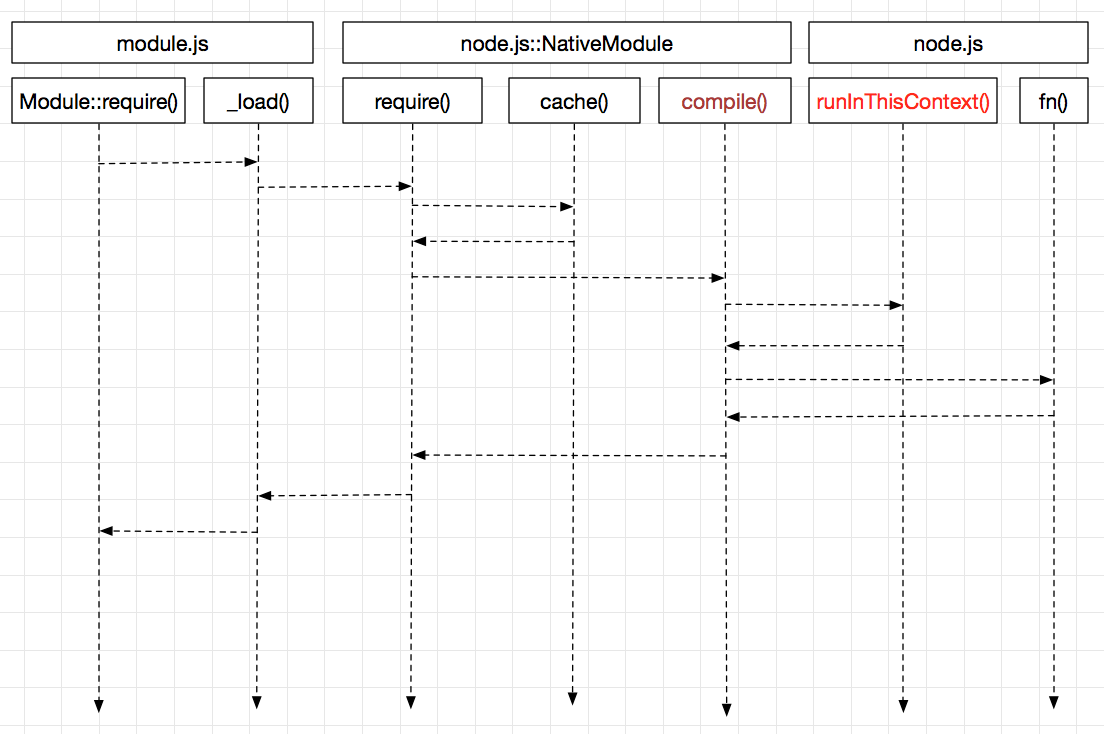
其实加载js核心模块和用户模块都会走到_load()接口,分水岭在于js的核心模块在node二进制文件编译的时候使用js2c.py编译进了./out/Release/obj/gen/node_javascript.h这个文件中,在_load函数中它先去判断要加载的模块在NativeModule中存不存在,如果存在,直接调用,如果不存在,那就是js用户模块,走另一个逻辑分支。现在我们探讨的是js核心模块,直接逻辑就进入了NativeModule。
在NativeModule的require中有一个细节,他并不是每次都重新加载,第一次加载相应的模块以后,便存在缓存中,下次直接从缓存中取,以加快效率:
1 | var cached = NativeModule.getCached(id); |
cache()接口的作用就是把第一次加载的放进缓存,它是一个对象函数不是类的静态函数:
1 | NativeModule.prototype.cache = function() { |
compile函数虽然很短,但值得详细推敲一下:
1 | NativeModule.wrap = function(script) { |
得到要加载的模块的源码后,nodejs执行了一个wrap操作,这个wrap把所有代码外部包了一层function。而exports、require等就是这个函数的形参。这也就解释了为啥用户感觉require,exports用户没有声明就能用。执行完了runInThisContext后,相当于是把这个模块声明了。fn()则是传入参数,执行构造函数,生成对象,至此这个模块就已经加载完成可以使用了。
值得注意的一点是,这里传入的require是NativeModule.require,后面我们会发现,加载js用户模块的时候传入的是Module.prototype.require。这是相当合理的,因为在引入关系上,js核心模块只有js用户模块才能引入,这个方向不能反,当然js用户模块也能引入js用户模块。所以如果后者传入NativeModule.require也是不合理的。
现在对于runInThisContext()接口我们的了解仅限于js层面,那么它究竟是怎么被传入v8解析并执行的呢:
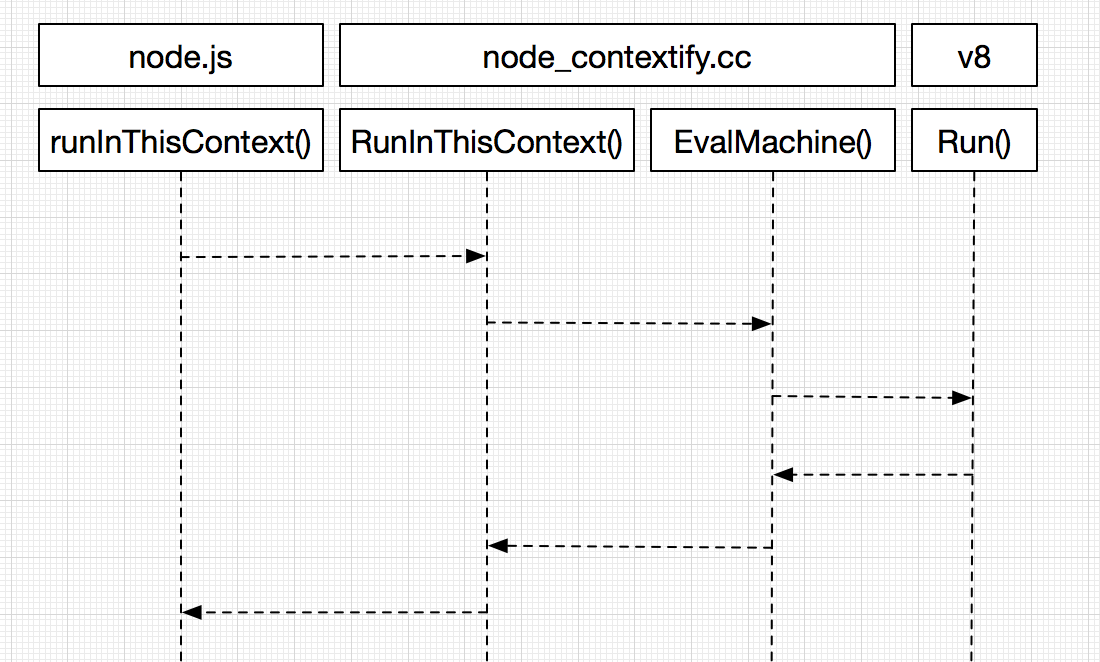
从js到C++,我们可以看到,js层调用了process.binding,获取了contextify模块(C++核心模块)的ContextifyScript对象,执行这个对象的RunInThisContext方法。
1 | var ContextifyScript = process.binding('contextify').ContextifyScript; |
在EvalMachine里,如其名就是执行js代码了,主要部分如下:
1 | ContextifyScript* wrapped_script = Unwrap<ContextifyScript>(args.Holder()); |
至于这些script是调用哪些接口生成的,比如PersistentToLocal、BindToCurrentContext具体做了哪些工作,则需要阅读v8的api文档或者v8的源码了,不在本文的范围之内,日后会再介绍。
2.c++核心模块加载原理
上一节已经有提到了,C++核心模块的就是通过process.binding(‘xxx’)导出的。
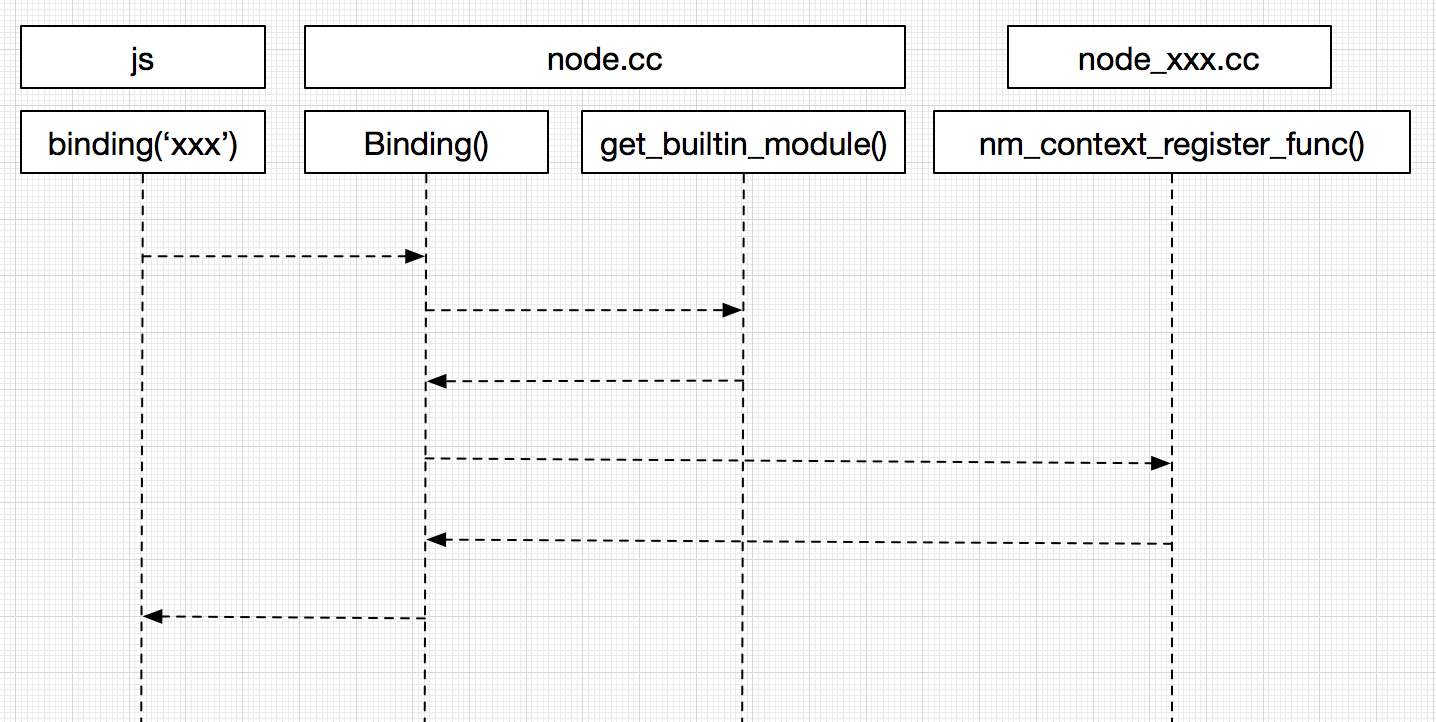
而这个nm_context_register_fun()则是在src/xxx.cc中通过NODE_MODULE_CONTEXT_AWARE_BUILTIN注册的,以node_buffer.cc为例:
1 | NODE_MODULE_CONTEXT_AWARE_BUILTIN(buffer, node::Buffer::Initialize) |
node_module的结构如下(在node.h中):
1 | struct node_module { |
有如下疑问:nm_register_func和nm_context_register_func在功能上有什么区别,通过在项目中寻找这两个词,发现
1 | NODE_MODULE(modname, regfunc) |
这个宏用于注册nm_register_func,
1 | NODE_MODULE_CONTEXT_AWARE_BUILTIN(modname, regfunc) |
这个宏用于注册nm_context_register_func,
src下的内建模块使用的都是后者来注册的,node项目中没有找到NODE_MODULE注册模块的地方。
在node.cc对nm_register_func以及nm_context_register_func的使用上也基本没差,如果一个没有就调用另外一个,仅仅在Binding接口中有区别:
1 | exports = Object::New(env->isolate()); |
只能猜测process.binding所引入的模块(C++核心模块)要使用nm_context_register_func,另外一个得为NULL。要是想扩展C++核心模块的开发者要注意这点了,不然无法正常引入,是个坑啊。
node_module在组织上是通过链表的形式,有新的模块来了,就会把它放到链表的头部,nm_link就是指向下一个模块的指针。
1 | static node_module* modpending; |
这四个静态变量分别表示四个链表,内建模块在加载时会被放入modlist_builtin,C++用户模块会被放入modlist_addon,如果src下的文件不是内建模块,在启动时他会被放入modlist_linked。
更具体地:
1 |
使用上面的宏注册的C++模块,会被放入modlist_linked;使用下面的宏注册的C++模块会被放入modlist_builtin。
至于modpending,笔者还不是很懂,它和modlist_addon是一对。加载C++用户模块的时候它会放入modpending,然后再是modlist_addon。但是它是在哪里放入modpending的,还不清楚,日后懂了会更新。