继上一篇:
这篇将会对C++用户模块以及js用户模块的加载流程作一个简单的分析。
3.js用户模块
只要是用户自己写的js模块,都归在这一类,包括通过npm install得到的模块也属于这个部分。
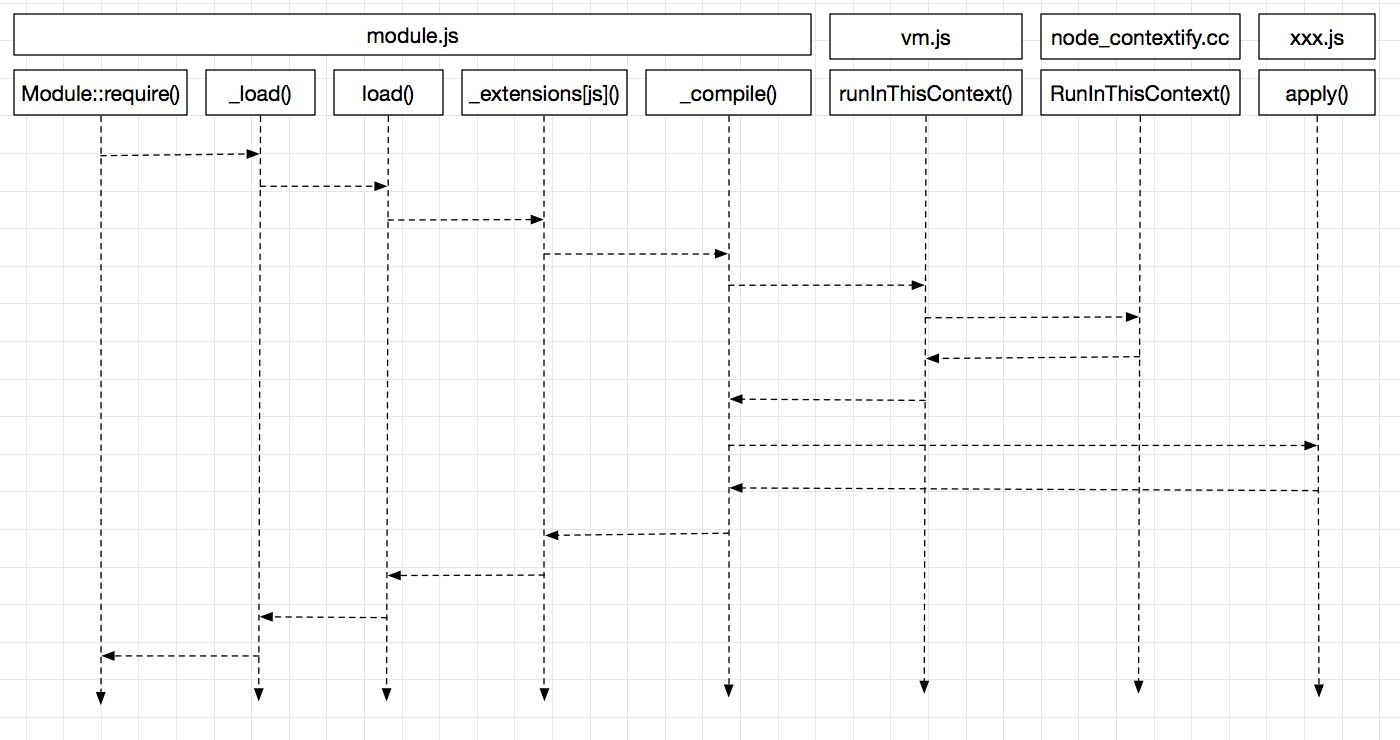
在_load()接口中,会首先判断要加载的模块是不是js核心模块,在这里逻辑就不走进去了,而是直接新建一个模块对象,并且把它放进缓存中,以加快下次加载的速度。
1 | var module = new Module(filename, parent); |
有一点让我很意外,比如我在node命令行下执行的是require(./abc.js),在这部分代码的上下文中,filename我原本以为会是abc.js,但是事实上是/Users/apple/Desktop/abc.js(我在/Users/apple/目录下执行的node命令,该目录下存在abc.js这个文件)。
这个filename是通过这行代码获得的:
1 | var filename = Module._resolveFilename(request, parent); |
这样带来的好处是同一个进程可以require两个不同实现的同名模块,但是前提是这两个同名模块必须位于不同的目录下面。
有一点需要注意,如果给的模块不是绝对路径,node会根据以下顺序,逐步去文件系统寻找
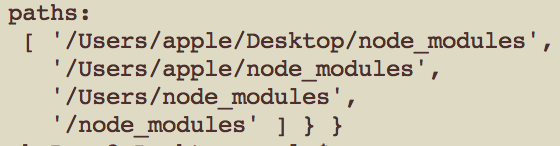
而且寻找的时候会按照不同情况去匹配模块类型(文件、自定义扩展名文件、包文件、默认出口为index.js的包文件),如果没匹配到就尝试下一个。所以nodejs在动态引入模块的时候,处理不当会造成很大的资源浪费,如有可能,将它写进NativeModule将会是一个很好的选择。
插一句话,对于node.js能支持require(‘./abc.cpp’);其中cpp文件里面是js代码。我并不觉得这是一个很好的feature。这样在一定程度上可以容忍用户编码的时候一个不小心的输入错误,但这个错误导致的是加载错一个文件,这在程序执行中却是无法容忍的大错。我觉得一个高级语言(nodejs可以理解成对js语法的扩展)的设计原则是简单、给开发者更少的选择、使他们编码既快速又不容易出错。但这个feature却是违背了这个原则,它同时带来了缺陷,就是使运行效率降低,node的这个特性我觉得可以去掉。
1 | if (!trailingSlash) { |
有兴趣的读者可以去研究下Module._resolveLookupPaths这个函数,这里面分了多种情况去生成paths数组。
在load接口中,默认会调用”.js”的extentions函数:
1 | var extension = path.extname(filename) || '.js'; |
1 | // Native extension for .js |
在_compile中,与编译NativeModule一样,会把整个js文件的内容,装进一个function内部,再一步步进入C++层编译,最后返回一个compiledWrapper对象。
1 | // create wrapper function |
编译完成后,最后再传入各种参数,执行,整个模块就算是顺利引入了。
1 | var args = [self.exports, require, self, filename, dirname]; |
4.C++用户模块
这个模块引入的文件是以.node结尾的二进制文件。它与C++核心模块的区别是不会被编译进node可执行文件中。当用户需要编写cpu密集型程序时,编写C++用户模块将会是一个很好的选择。require的用法也与js用户模块类似。它的引入流程如下图:
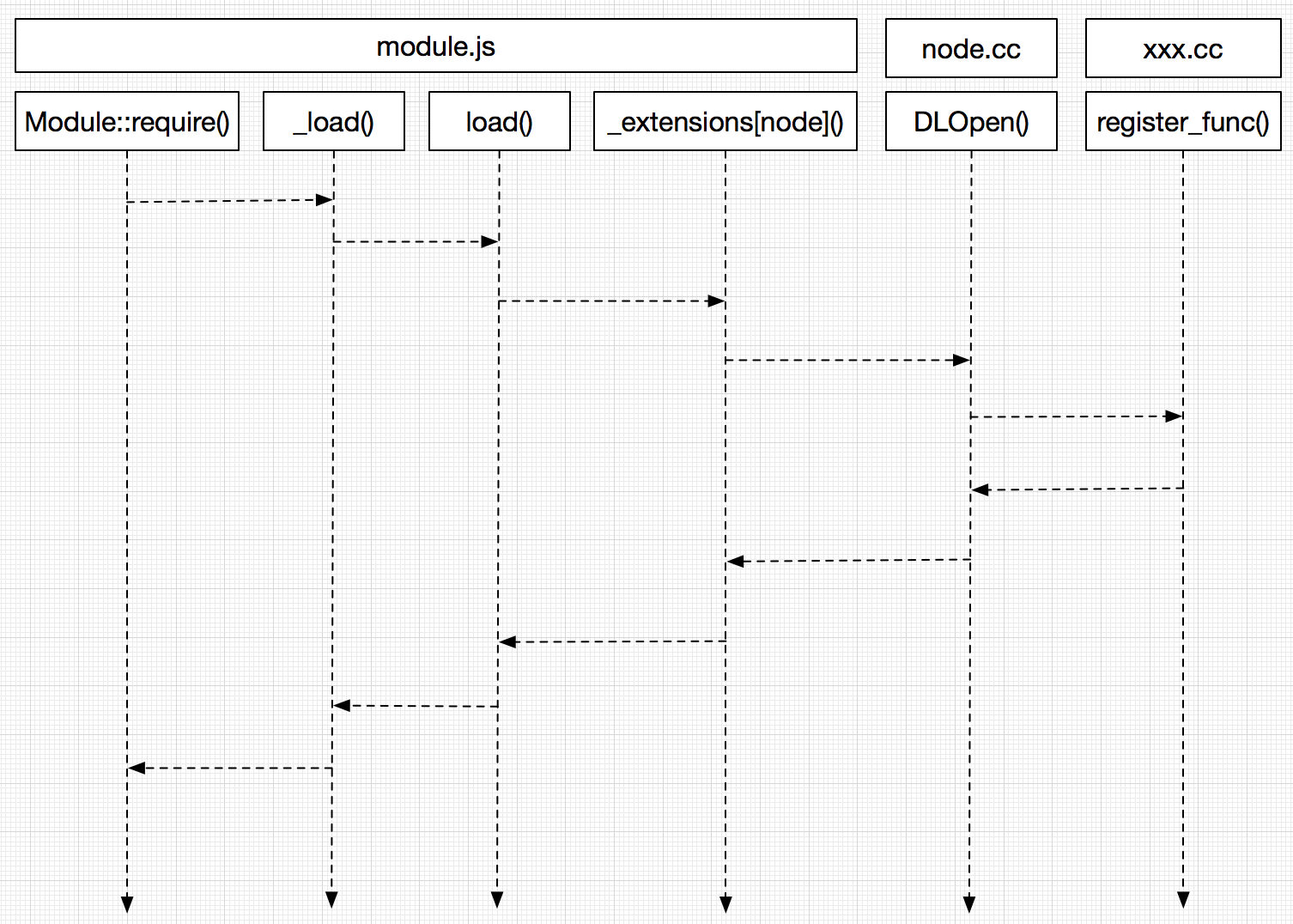
到_extensions函数之前都与加载js用户模块一样,包括解析文件名、获取paths路径、模块缓存策略。
_extensions在这里调用的是
1 | // Native extension for .node |
dlopen这个函数定义在node.cc中,接受两个参数,第一个是module对象本身,第二个是文件名,在DLOpen()中,首先取出模块以及它的exports对象:
1
2
3
4
5 Local<Object> module = args[0]->ToObject(); // Cast
node::Utf8Value filename(args[1]); // Cast
Local<String> exports_string = env->exports_string();
Local<Object> exports = module->Get(exports_string)->ToObject();
然后调用libuv的接口、打开文件载入内存、把模块压入链表modlist_addon头部、最后再传入exports等对象执行模块的注册函数,至此,就顺利引入了。
1 | if (mp->nm_context_register_func != NULL) { |
关于注册函数nm_context_register_func、nm_register_func的区别以及模块链表的特性,请参见上一篇文章。